Traitement des données
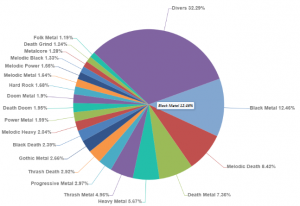
Avec mes coéquipiers, nous avons décidé de récupérer des informations concernant les groupes de métal dans le monde. Nous avons chacun crawlé un site différent en python à l’aide du framework de crawl et d’indexation Scrapy. Nous y avons récupéré plusieurs informations telles que les noms, le pays d’origine, le genre, le statut (splité, sans nouvelles, actif), la date de formation ainsi qu’une photographie du groupe dans une base de donnée MongoDB.
A partir de l’url de site que nous souhaitions crawler, notre spider était capable de parcourir chaque page de groupe pour y récolter les informations ciblées. Nous avons utilisé les chemins xpath afin de lui indiquer quelles étaient les données à récupérer. L’utilisation d’un pipeline permit de nettoyer les données récupérées avant de les enregistrer en base de donnée MongoDB
Nous avons ainsi récolté des informations concernant 79 748 groupes.
Le site
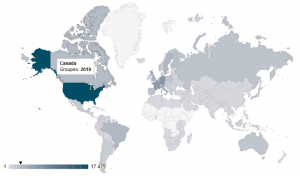
Une fois les informations enregistrées en base de données, nous avons réalisé notre site en NodeJS en utilisant un routeur pour des url dynamiques. Les vues du site ont été conçues en utilisant le moteur de templates Twig.
L’utilisation des librairies javascript d3, Canvas et Google Geochart nous ont permis de représenter graphiquement les données crawlées.